分析分布直方图和再现性指数 Cp、Cpk 是否足够?通过构建休哈特控制图开始您的分析!
该材料由 AQT 中心科学主任准备 谢尔盖·格里戈里耶夫
免费获取文章不会以任何方式降低其中所含材料的价值。
在一家研究和生产公司的质量保证部门,我看到了一个关键质量指标分布的直方图,专家在调查严重事故的原因时使用了该指标;他们的争论更像是在咖啡渣上算命。没有人知道这一指标的生产过程的统计状态。
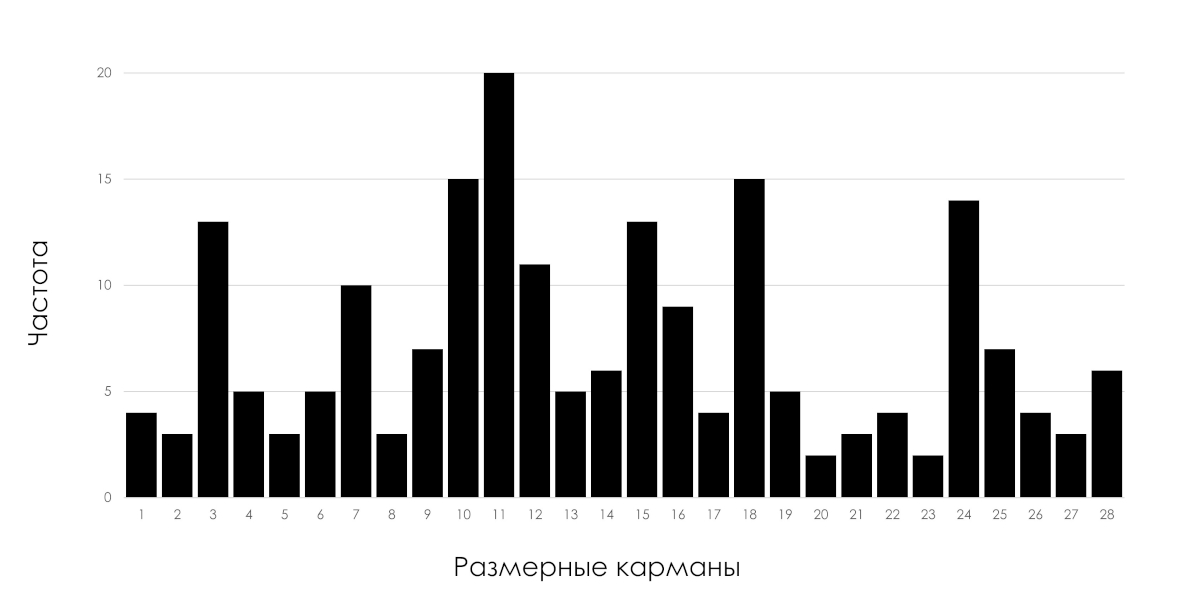
米。 1:关键质量指标的分布直方图。
它为什么如此重要?!事故是结果,而不是原因。
上图所示的指标分布直方图可以是统计上稳定(可预测)和统计上不稳定(不可预测)过程共同作用的结果。
如果制造记录了该直方图的零件参数,为什么不维护休哈特控制图来跟踪过程的统计状态?即使零件的控制参数仍在公差范围内,控制图也会尽快报告导致零件故障的生产过程问题。生产人员有理由停止生产过程,直到确定并纠正问题的具体原因。我强调,对于受工艺紊乱影响期间生产的零件,有必要做出进一步通过或拒绝它们的决定,即使这些零件符合公差范围。由处于统计不稳定(不可预测)状态的过程生产的零件不是同质的,而是显着不同的。用于确定均匀性的公差限值不适用。对于特别关键的部分,了解这一点非常重要。
为了改进它而选择与之相关的两种相反类型的措施取决于所分析过程所处的统计状态。详细解释见文章“ 变异性的本质 ”。
以下是爱德华兹·戴明对解释密度直方图问题的解释,该问题引起了这种情况。
“统计学课程通常从分布及其比较的研究开始。在课堂上或书本上不会警告学生出于分析目的(例如过程改进)分布以及平均值、标准差、卡方值、t - 的计算除非在统计控制状态下获得过程数据,否则统计等都是无用的
因此,检查数据的第一步是了解数据是否是在统计控制状态下获得的。分析数据最简单的方法是按照点出现的顺序排列点,看看是否可以从数据形成的分布中学到什么。
作为一个例子,让我们看一下似乎具有最佳特性的发行版,但它不仅无用,而且具有误导性。图2为某型号相机使用的50个同类型弹簧的测量结果分布。通过在20g的力下拉伸来测量弹簧。
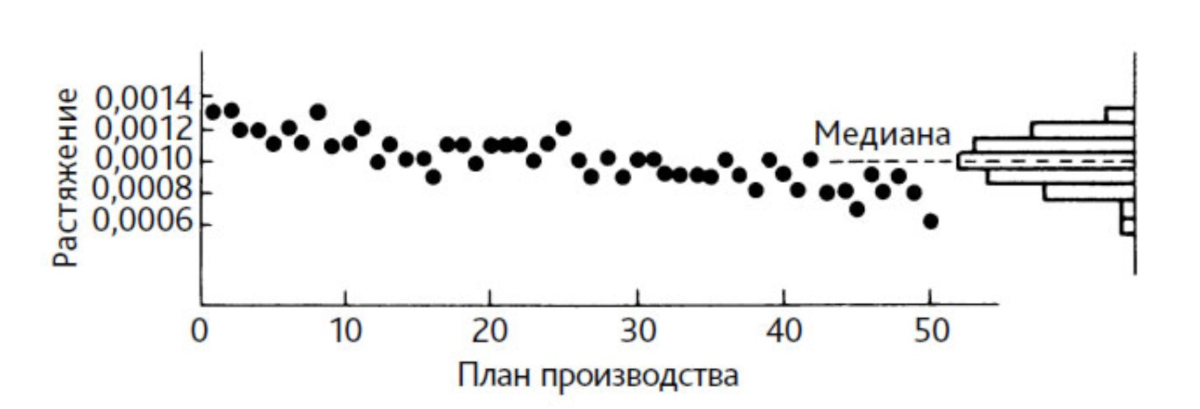
米。 2. 过程散点图以及按制造顺序测试的 50 个弹簧的分布直方图。资料来源:[2] 爱德华兹·戴明,《克服危机》一书,第 224-225 页
如果不考虑生产时间,数据(图2)形成对称分布,但如果按照弹簧的生产顺序排列,则发现这种分布毫无用处。例如,分布不会告诉我们成品弹簧可能属于什么公差。原因是没有可识别的过程。
分布看起来相当对称并且在公差范围内。人们很容易得出这样的结论:该过程处于令人满意的状态。然而,按生产时间顺序排列的拉伸值呈现下降趋势。
制造工艺或测量设备有问题。任何使用图 2 所示的分布的尝试都是无用的。例如,计算给定分布的标准差不会产生可用于预测的值。它没有提及该过程,因为它不稳定。
因此,我们学到了一个非常重要的教训——要分析数据,你需要查看它。将点按生产顺序或其他合理顺序排列。对于某些问题,简单的散点图很有用。
如果有人尝试使用此分布来计算过程再现性指标怎么办?他将陷入一个难以逃脱的陷阱。过程不稳定。根本不能归因于它的可重复性。
分布(直方图)仅显示过程的累积数据,而没有说明其再现性。一个过程只有稳定时才可重复。过程再现性是通过使用控制图而不是分布本身来实现和确认的。正如我们已经看到的,即使是一个简单的流程图也能说明该过程的可重复性。”
在我们的 软件 个体值分布的直方图由直方图下方的散点图进行补充(图3),它展示了直方图隐藏的有关过程的信息,是数据分层的最佳基础。
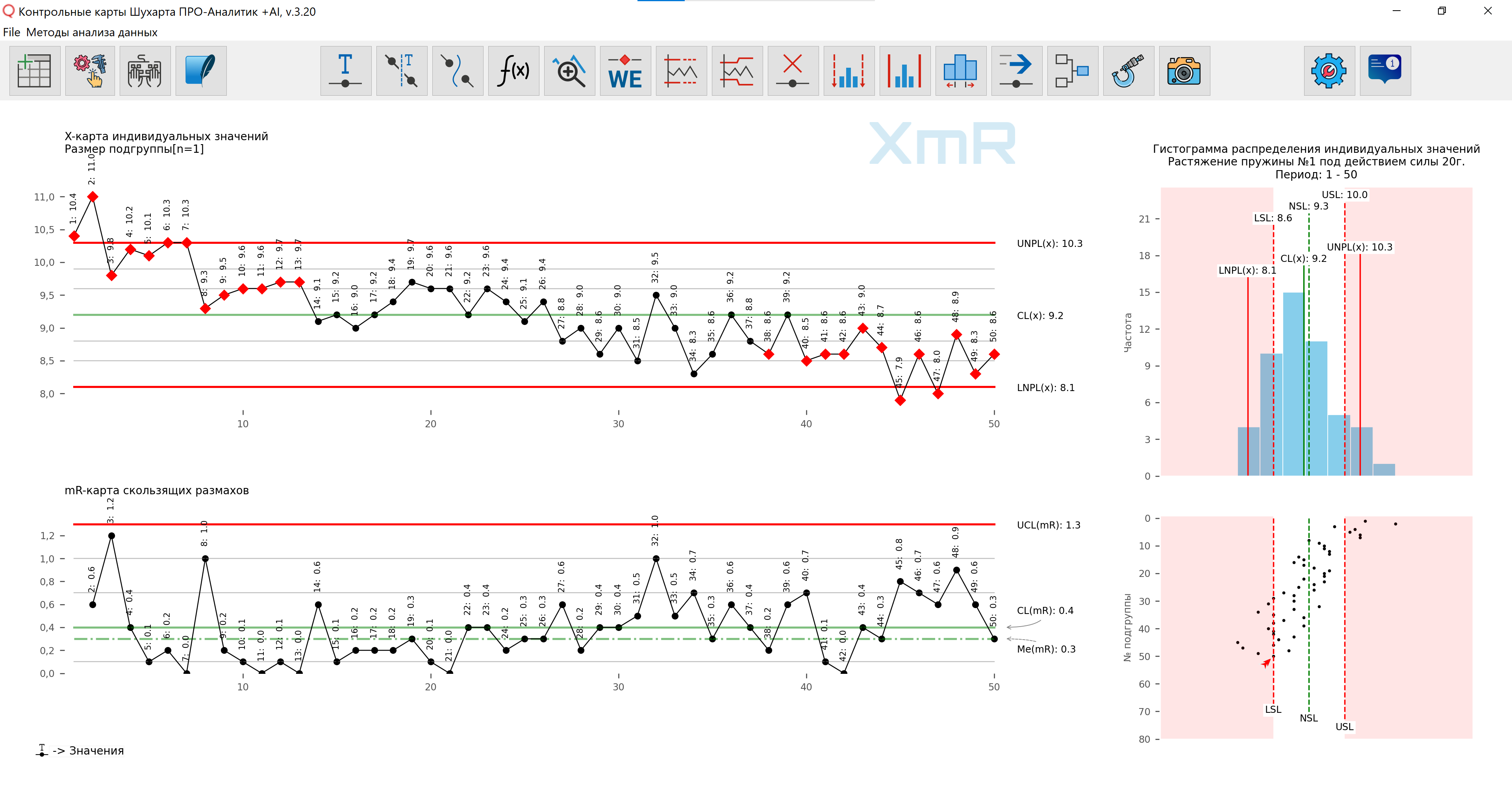
图 3. 使用我们开发的数据准备的图 软件 。
您应该根据数据构建简单的单个值和移动极差的XmR控制图,按照产品输出的时间顺序,即输出,和 不是样品测量的顺序 。
常见的错误!收到检验的产品转移到公共堆中,检验人员按照先取方便并按顺序记录的原则进行挑选;产品输出的时间顺序丢失。
请注意提前收集这些数据,以某种方便的方式标记生产顺序。此外,直方图中的数据可以属于不同类型的变异源(机器、操作员、主管、原材料批次等)以及同一类型内的变异源(例如,机器 1、机器 2、机-3)。尽管休哈特控制图擅长分析来自混合变异源的数据,但当您使用有关可用于会计的变异源的信息(在变异源的背景下构建控制图)时,您将获得更多有关变异源的信息。过程,因此,您将有更多改进的机会。再次强调,一定要提前收集这些数据。并注意确保数据可追溯的程序,这将极大地方便识别因果关系。
在下一个级别,您可以使用 XbarR 子组平均值和范围图来分析流程的输出。
因此,对于 Shewhart XbarR 控制卡,您将需要 将数据合理分组为子组 考虑变异的类型和来源。例如,要分析某一指标对特定运算符的依赖性,将数据分组应确保来自不同运算符的数据不会落入任何一个子组。
管理者经常提到臭名昭著的“人为因素”来解释绝大多数企业问题。当然,每个人都是不同的——不然怎么可能呢?!但我要提醒你的是,在分析人的工作时,你观察的是各个员工与你的管理层构建的系统交互的结果,而系统对流程输出的影响远高于个人员工个人的贡献,除非他们是拥有自己的颜料、画笔和画布的艺术家。
适合有好奇心的人。
使用直方图(泛化)还有另一个陷阱 - 各个值所属的直方图口袋的大小(列宽)。结果可能是,与放入右侧口袋的尺寸略有不同的尺寸最终会放入左侧口袋。对于落在公差带内和超出公差带的产品,也会发生同样的情况,请参阅定义 田口质量损失函数 。我针对这个案例采用了田口的方法。因此,在直方图的一个区域内,所有单独的值都添加相同的频率,从而增加了柱的高度。如果这些值稍微超出口袋的边界,则它们分别落入右侧或左侧的口袋中。但落入一个口袋的值之间的差异远大于位于相邻口袋中公共边界的值之间的差异。因此,直方图是一个有用但具有概括性的工具,那些比较相邻条形的人很容易被误导。此外,直方图条的大小很大程度上取决于直方图袋的大小;您可以通过为同一数据系列构建具有不同口袋大小的直方图来轻松验证这一点。我们的软件将帮助您使用离散数据进行这些简单的实验。 设置自定义直方图口袋大小 ,对于连续值,函数: 沿 X 轴和 Y 轴缩放直方图 。
重现性指数 Cp、Cpk
对于不可预测的过程计算再现性指数 Cp 和 Cpk 是没有意义的;根据定义,不可预测的过程是不可重现的。
即使对于处于统计控制状态的过程,再现性指数也只能在 Cp、Cpk 对中使用,否则您很容易被它们中的每一个误导。在没有以直方图形式进行额外图形表示的情况下,理解再现性指数的实际含义会给分析师和他试图向其呈现这些指数的人带来不必要的认知负担。
生存空间指数 (Cp) 并未说明过程相对于公差限值的位置、在公差边界之内甚至完全在公差边界之外。图3和图4中的生存空间指数Cp具有相同的值。
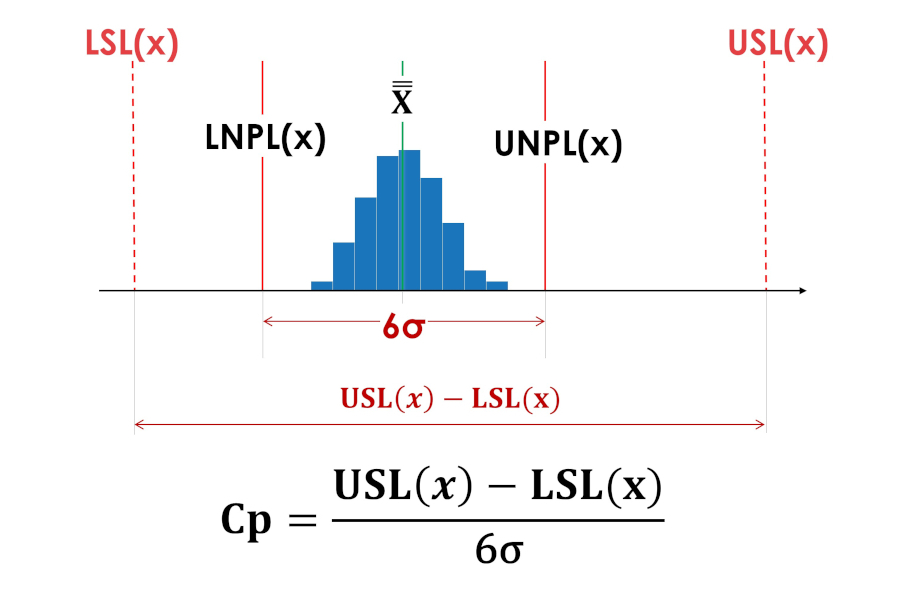
米。 3.实际过程再现性指数Cp(过程生命空间指数)。 LSL(x)——公差下限; USL(x)——公差上限; LNPL(x) - 过程的下自然边界; X——过程平均值的平均值; UNPL(x) - 过程的自然上限。
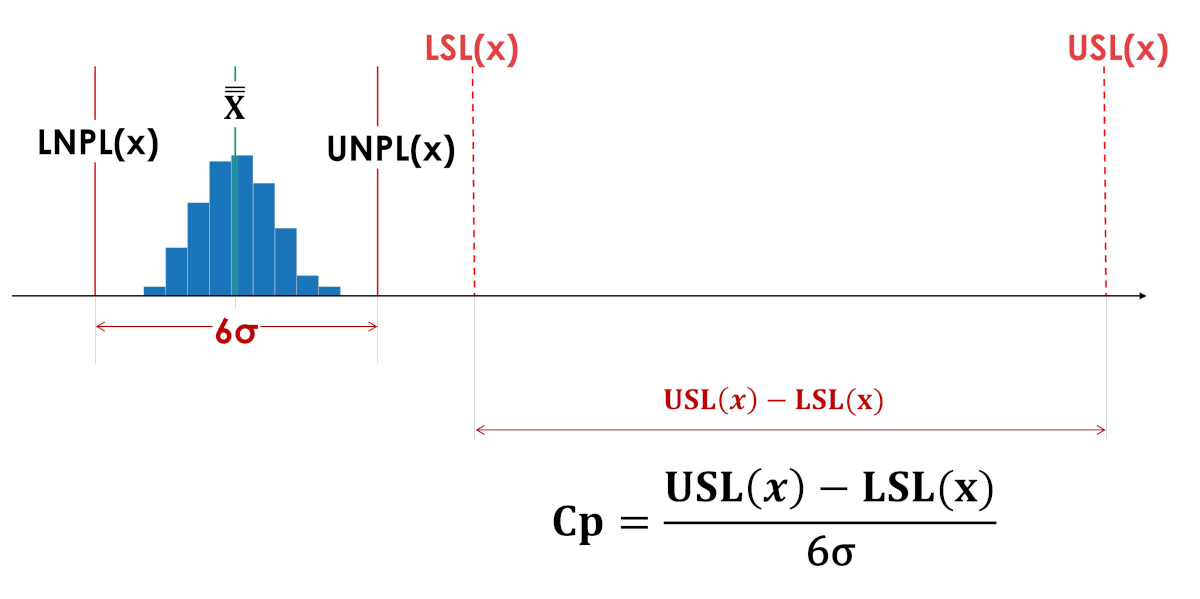
米。 4. 过程被人为地超出了容许限度。
定心指数 Cpk 没有给出偏离公差域中心的偏移侧的概念,因此隐藏了改进工艺的重要信息,并且如果该值与公差域中心不一致(非对称公差域),则毫无意义。
图5和图6中的中心性指数Cpk具有相同的值。
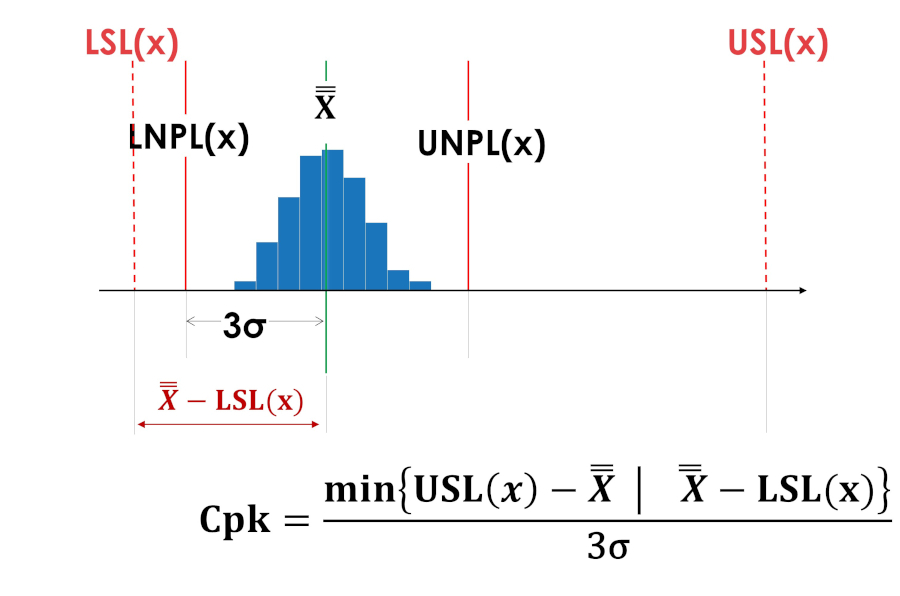
米。 5. 工艺的定心指数Cpk移至公差范围的下限。
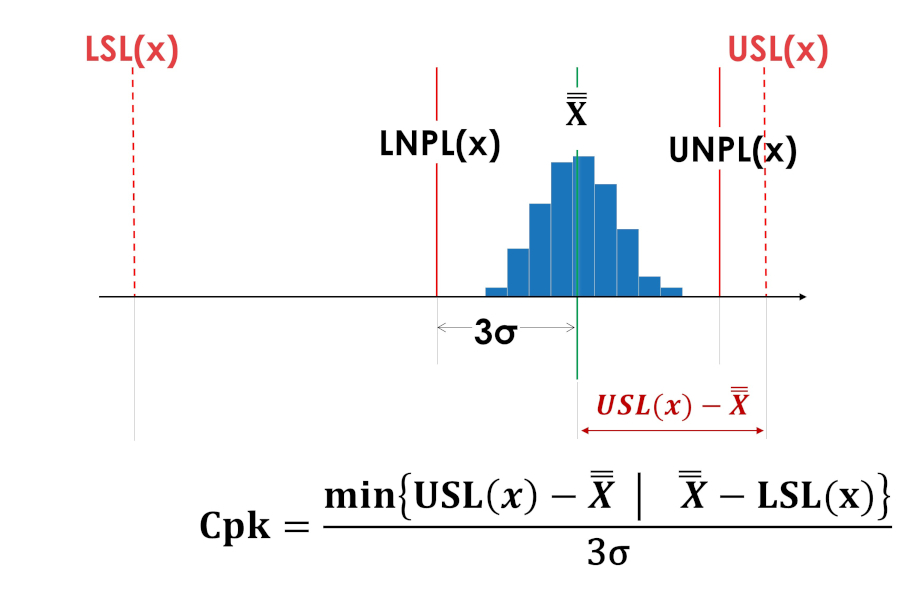
米。 6. 工序的定心指数Cpk移至公差范围的上限。
再说一遍,通过简单的图形方法提供了有关流程以及需要采取哪些措施来改进流程的更多有用信息,每个人都可以理解:休哈特控制图、分布直方图和受控值的简单点图,并辅以容忍限度。
例如,假设您被告知以下再现性指数值:Cp=2.6; Cpk=0.9 而不是显示图 7 中呈现的图表。哪些信息更容易且更快地感知?哪种形式的信息传输可以更全面地了解该过程?
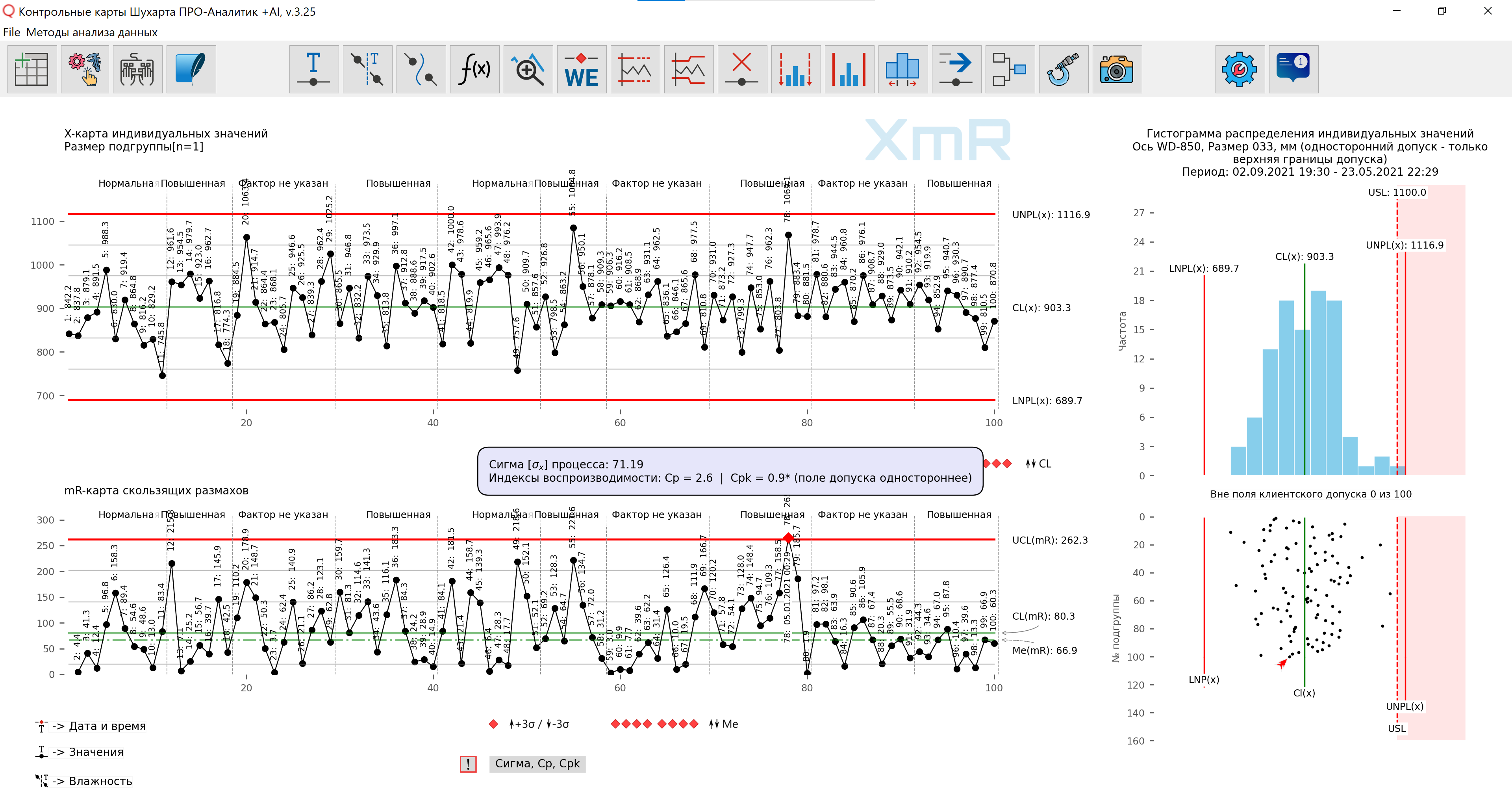
米。 7. 哪些信息更容易、更快地被感知?哪种形式的信息传输可以更全面地了解该过程?