对数据进行合理分组,以有效利用子组平均值和范围的控制 XbarR 图表
来源:Donald Wheeler 博士向我们提供的文章:[35] 理性分组。过程行为图/理性分组的概念基础。过程行为图的概念基础,Donald J. Wheeler。
翻译家和科学编辑:Sergey P. Grigoryev
免费获取文章不会以任何方式降低其中所含材料的价值。
有效使用控制图的一个重要方面是它们回答正确问题的能力。为此,将数据分配到子组的方法必须与数据的结构相对应。这通常意味着来自某些“小区域”(空间、时间、生产批次)的数据应分组到每个子组中,以便子组内的数据尽可能同质。之所以强调最小化子组内的变异,是因为正是这种变异用于计算控制限。控制限取决于平均范围,而平均范围又取决于各个组的范围,反映了子组内的变化。子组内的变异用于设置控制限,控制限决定了子组之间可接受的变异程度。
均值控制图提出的问题是:“根据组内变异,组均值的变化是否超出应有的范围?”换句话说:“鉴于子组内的变异性,组均值之间的差异是否可以检测到?”
子组极差图询问“子组内的变异在子组之间是否一致?”或者,换句话说:“假设子组内平均变异,子组之间的变异差异是否可以检测到?”
这两个问题的区别将通过几个例子来说明。
板材厚度
用于制造加垫面板护套的 30 英寸(762 毫米)宽的乙烯基片材是在自动过程控制器的控制下挤出的。该自动过程控制器的输入设备是传统的 Beta 扫描仪,用于测量乙烯基厚度。工程师想要研究沿距离乙烯基片材左边缘 10 英寸的一条轨迹的厚度读数,因此他收集了该轨迹的所有数据,并将其绘制在 XbarR 子组平均值和范围参考图上,使用大小为 4 的子组。
通过使用大小为 4 的子组,他确保每个子组代表大约两分钟的流程工作。他认为,这使得每个子组的挤出过程中出现正态变化(由于共同原因而产生的随机变化)。图1中的平均控制图显示,自动控制器以20分钟左右的周期上下调节过程。虽然平均厚度为48.5毫米,但五六分钟后可能会达到49.5毫米,六分钟后会降至47毫米。这种厚度的变化影响了真空成型时乙烯基的加热和拉伸方式。这种厚度的变化在下一步中造成了浪费,但平均而言,乙烯基的厚度是正确的!
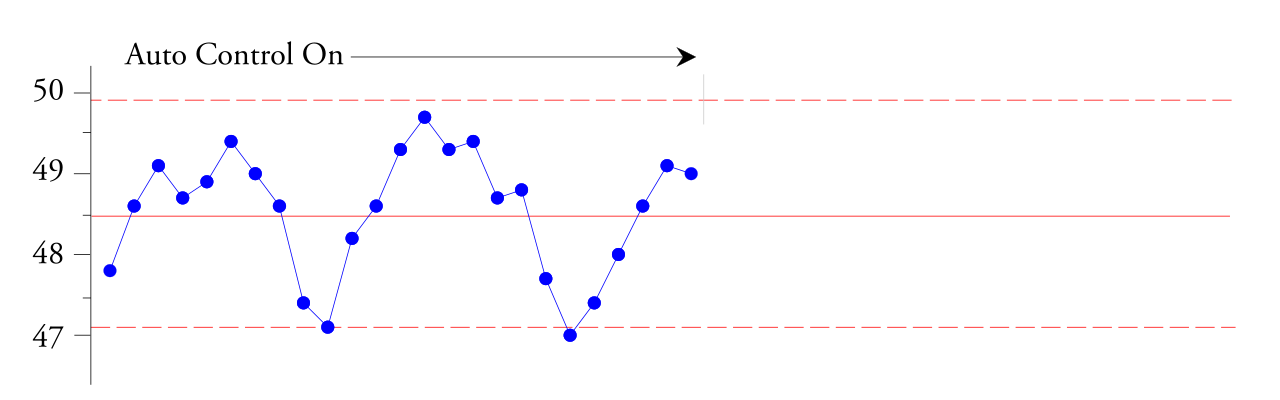
米。 1. 自动控制过程中乙烯基片材平均厚度分组的 XbarR 控制图。
控制限度内的点呈上下趋势,告诉我们这种自动过程控制器还不够 阻尼的 ,没有保持良好的稳态响应,需要帮助。根据创建此 XbarR 控制卡的工程师的说法,“识别我们所看到的正弦波”很容易。根据图1中观察到的现象,工程师关闭了自动过程控制器。在接下来的 45 分钟内,它收到了新值,如图 2 右侧所示。
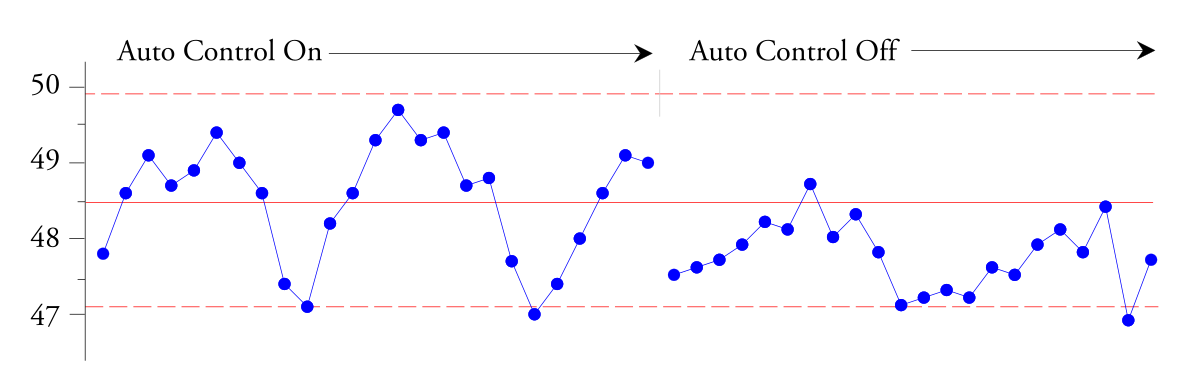
米。 2. 乙烯基片材平均厚度子组的对照 XbarR 图(续)。
这证实了大约一半的板材厚度变化是由自动过程控制器造成的。由于这些变化会导致有缺陷的输出,因此必须正确配置此自动过程控制器以消除这些 20 分钟的循环。请注意,从解释图表到制定所需操作的路径如何取决于数据的上下文以及数据如何组织成子组。
达到最大扭矩的时间
为了表征各批次橡胶混合物的固化性能,必须在实验室中测试每批次的样品。该测试测量橡胶样品固化时的扭矩。测试结果是达到最大扭矩所需的固化时间。由于三名操作员每个班次生产五批橡胶,因此实验室决定使用每个操作员的五个每日值作为其子组。这导致每个班次有一个子组,子组内的变异是每个操作员的批次间变异,子组之间的变异是操作员之间的变异和每日变异。由于所有操作员使用相同的橡胶磨生产相同的产品,因此我们期望在构建子组均值和极差的 XbarR 图时看到可预测的过程。
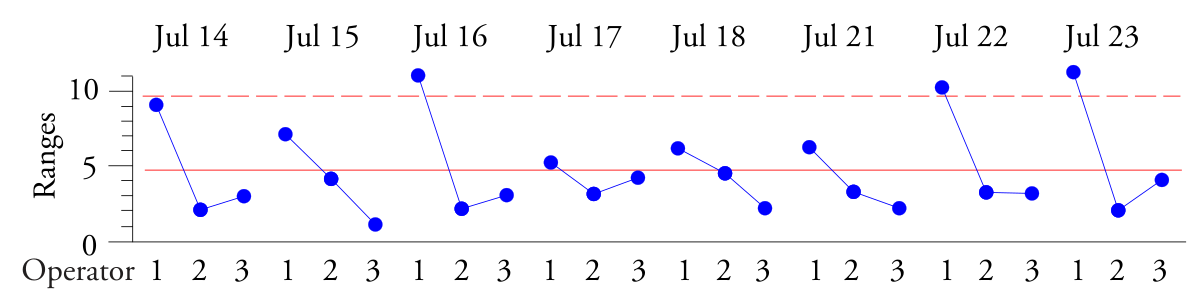
米。 3. 控制达到最大扭矩的时间子组范围的 R 映射。
组范围的 R 图显示出重复的高-低-低模式。操作员 1 生产的批次显示出比操作员 2 和 3 生产的批次更多的变化。虽然操作员 1 是一位拥有 30 年经验的高级操作员,但他没有正确混合批次。事实证明,这是因为操作员 1 失去了视力,无法清晰地进行手动混合。
再次强调,解释数据的关键是在控制图上组织数据。组范围的 XbarR 控制图显示子组内缺乏一致性,并且使用单个语句识别每个子组使我们能够理解图 3 中所示的模式。数据的组织决定了将在该子组中解决哪些问题。子组均值和极差的 XbarR 控制图。子组之间发生的位置变化将显示在子组均值的 X 地图上。不同子组内发生的变异变化将显示在组范围的 R 图中。在每种情况下,子组内的变异决定了检测出现的任何差异的标准。理解这一点是有效分析观测数据的关键。
在上面的第一个示例中,它是一个时序电路,提供了一个禁用自动过程控制器的简单实验。在第二个例子中,正是一种与数据结构相匹配的方法,导致了盲操作符的发现。在这两种情况下,根据上下文对图表的解释都会带来新的发现。这种思考方式的意愿与数据收集和构建的方式一致,是无法编程的。这取决于有人花时间和精力来查看图表并思考它们。这一直是并且将永远是有效使用过程行为控制图的一个组成部分。
对于某些数据集,合理的分组将非常简单。然而,对于某些数据集,可能有不止一种可能的方法将数据分成子组。以下示例属于此类。
注塑接头头
使用注塑成型将旋转接头一次制成四件。在收集这些数据时,这种制造方法代表了材料和技术的变化。因此,在投入量产之前,必须经过工艺认证。经理 Dave 决定在认证之前使用流程行为检查表来评估流程。
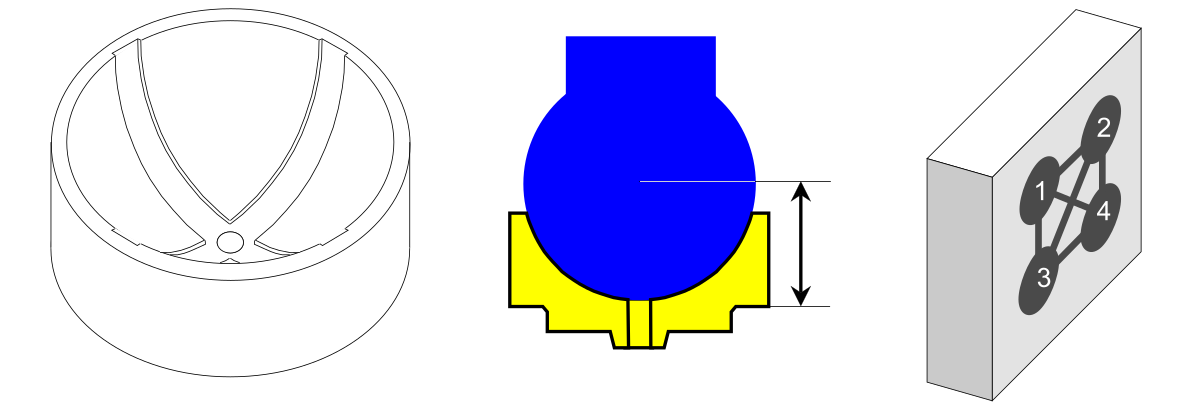
米。 4. 球头联轴器,厚度尺寸,模具有4个腔。
由于只有一个模具,只有一台压机和一名操作员参与认证过程。数据是球联轴器的有效厚度,以百分之一毫米为单位测量。由于球联轴器的一侧是凹形的,因此必须设计和制造特殊的量规来测量该厚度。仪表测量显示厚度超过 12.00 毫米。戴夫每天四次去冲压机收集连续五个冲压周期生产的零件。由于每个周期生产 4 个零件(每个型腔一个),因此他必须每两小时测量 20 个零件。戴夫小心翼翼地跟踪每个零件的周期和腔体。
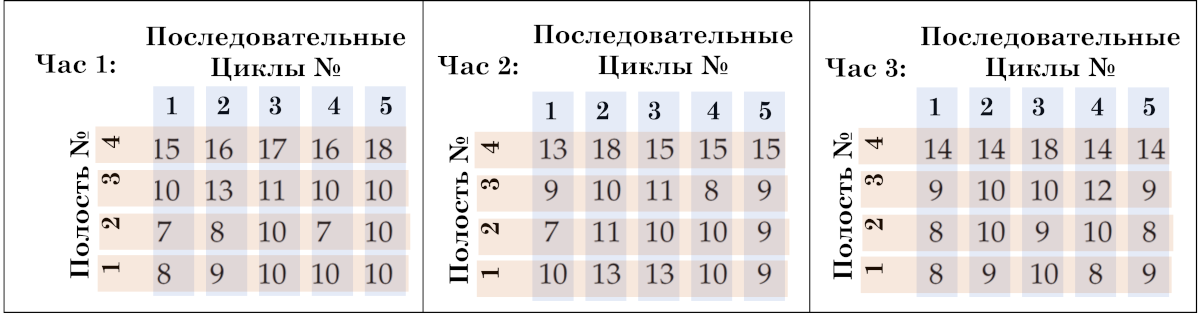
米。 5. 每小时球接头厚度数据的结构。小时,连续塞克勒斯,空腔。
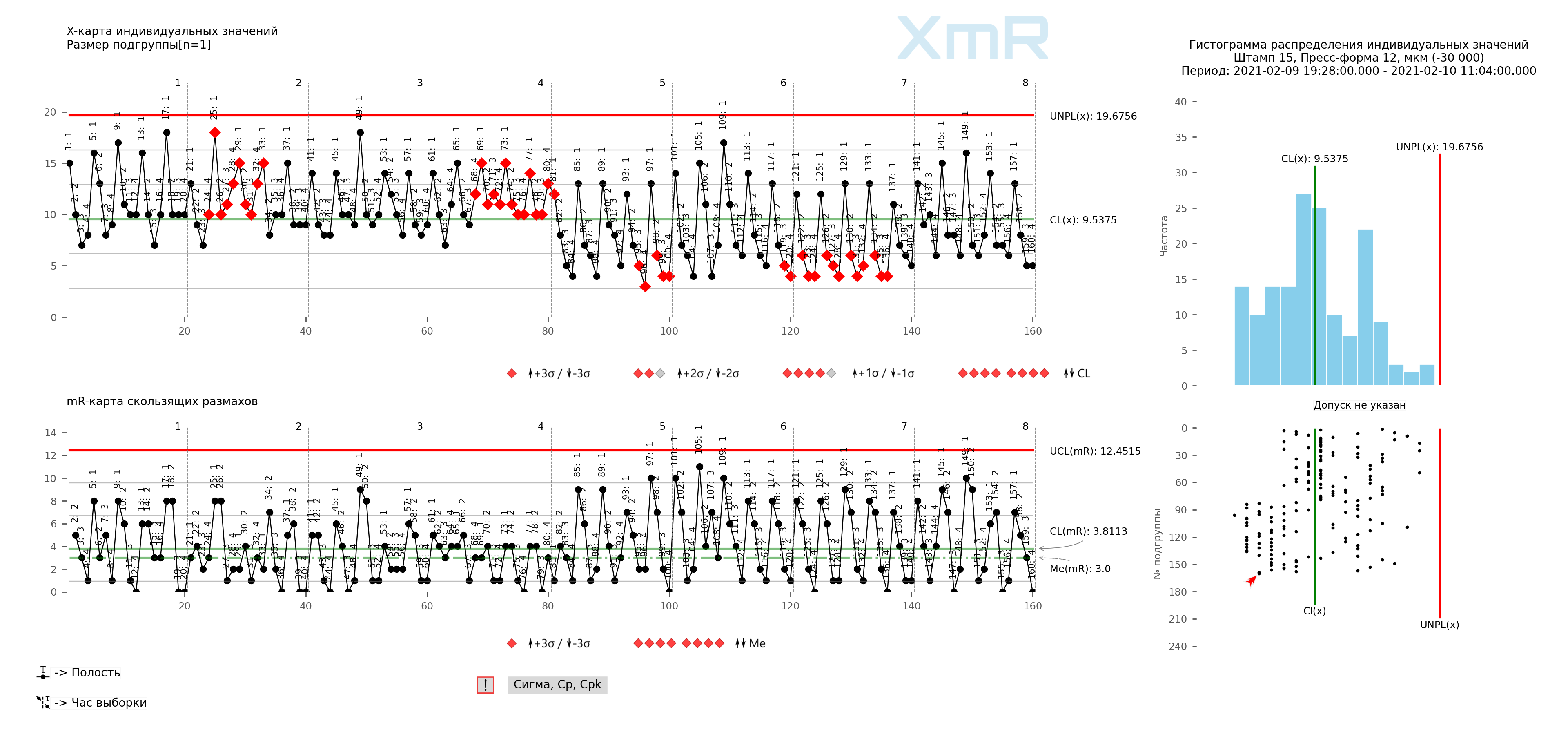
米。 6. 工艺进度图表上球联轴器厚度的每小时数据结构(单个值和滑动范围的 XmR 图表)。垂直分隔线:小时,所有点的签名:模具型腔。 该图纸是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 。
这些数据存在三个可识别的变异来源。有每小时的变化,由图 5 中 20 个值的不同集合(块)表示。有周期到周期的变化,由图 5 中的不同列表示(1、2、3、4、 5)。并且不同腔体之间存在差异,这在图 5 中用不同的线表示(1、2、3、4)。
我们将研究对子组均值和极差的 XbarR 控制图进行分组的不同方法,以及将数据组织到子组中对控制图解释的影响。在认证过程中,戴夫收集了六天的数据。为简洁起见,我们将仅使用前两天的数据。
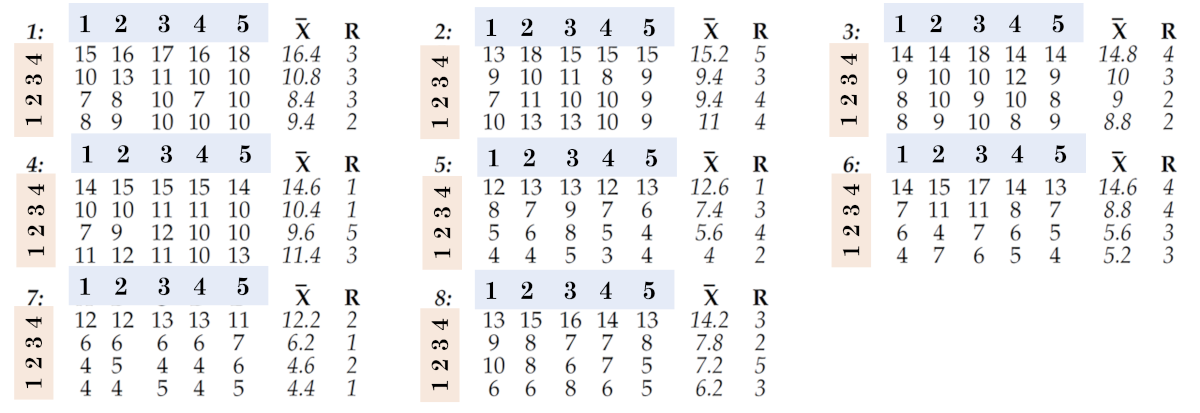
完整的数据集和第一次组织成子组如图 7 所示。每列四个值用于定义一个子组,这样我们的 160 个值就被组织成 40 个大小为 n=4 的子组。不同小时(1、2、3 等)的数据位于不同的子组中。当您更改时间时,您也会更改子组。因此,在第一次将数据组织成子组时,可以说子组之间出现了每小时差异(以及每日差异)。这里 XbaR 平均值图表将提出以下问题:
问题#1:几小时或几天之间是否存在明显差异?
在图 8 中,来自不同周期(1、2、2、4、5)的数据位于不同的子组中。当你改变周期时,你就改变了子组。因此,可以说,在这些数据的第一次组织中,子组之间出现了跨周期差异。这里,平均子组图还会提出以下问题:
问题#2:周期之间是否存在明显差异?
在图 8 中,来自不同腔体(1、2、3、4)的数据位于同一子组中。当您更改型腔时,无需更改子组。因此,可以说,在这些数据的第一次组织中,空腔之间的差异出现在子组内。所以这里的组范围图会问以下问题:
问题#3:腔体之间的差异是否一致?

米。 7. 第一种将数据组织成子组的方法。
平均值 - 9.54;平均范围为 7.63,得出如图 8 所示的控制限。通过打破图表的线条,我们可以通过分别为我们的眼睛提供每小时的参考来更容易阅读。尽管没有点超出限制,但子组平均图中有一个明显的信号。当 20 个平均值中的 20 个位于中心线上方,随后 20 个平均值中的 19 个位于中心线下方时,第一天和第二天之间存在真正的差异。子组范围图还可以显示每日差异。因此,我们对问题#1(几小时或几天之间是否存在明显差异?)的回答是肯定的,对问题#2(周期之间是否存在明显差异?)的回答是否定的,并回答问题#3(差异是否一致) ?在空腔之间?)可能“不”。
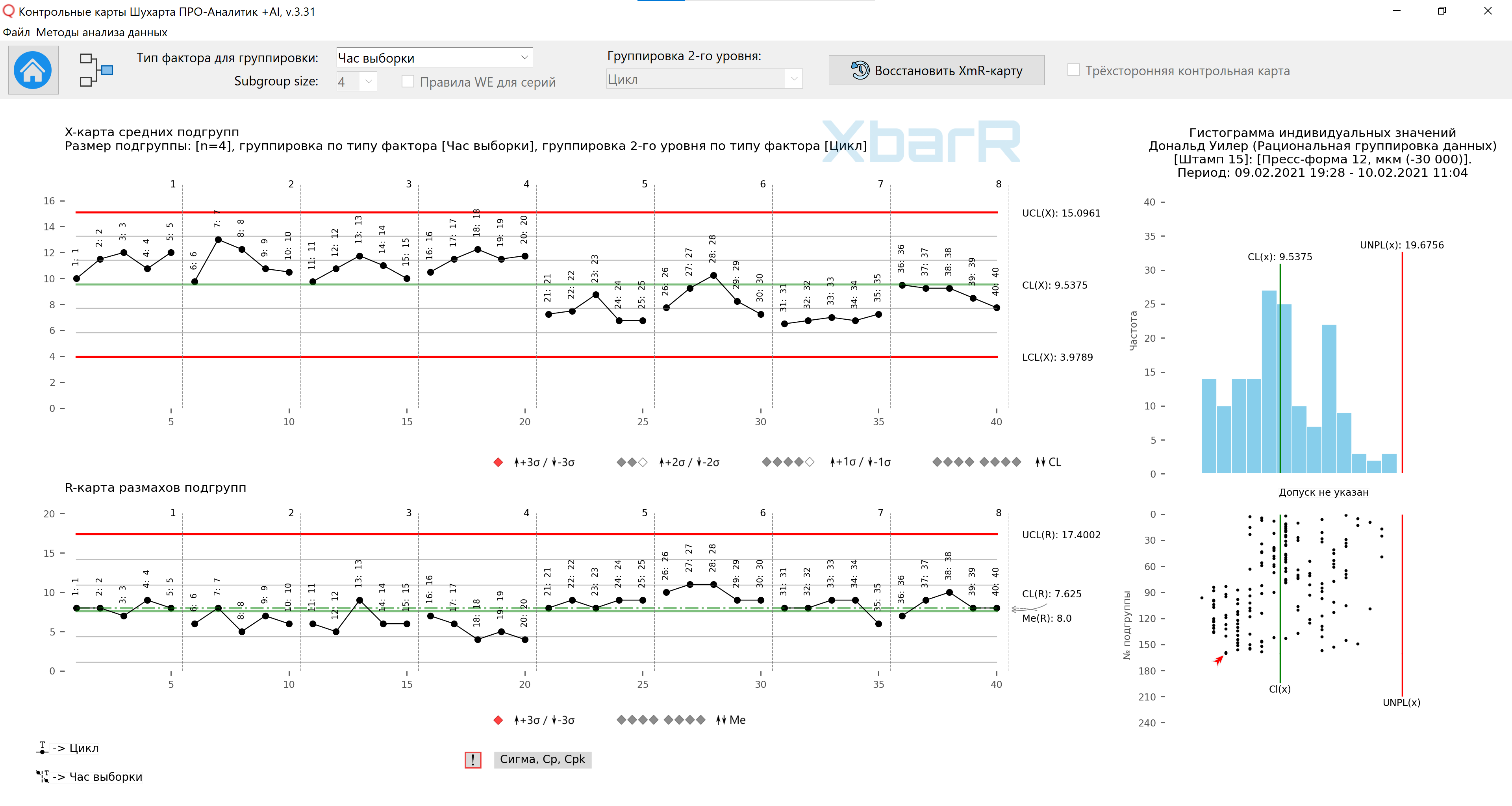
米。 8. 第一种组织子组数据方法的子组平均值和极差图。垂直线划分系列,数值从 1 到 8 - 采样小时数、所有点的签名 - 周期号。绘图是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 使用独特的 用于合理数据分组的自动化功能 根据选定的变异来源类型(包含因子的列)和子组的大小构建子组均值和极差的 XbarR 图。
将数据组织成子组的第二种方法
组织此数据的第二种方法如图 9 所示。其中,每行五个值用于定义一个子组,因此我们最终得到 32 个大小为 n=5 的子组。这里,来自不同时钟(1:、2:、3:等)的数据位于不同的子组中。当您更改时间时,您也会更改子组。因此,在第二个组织中,可以说子组之间每小时(和每天)都存在差异。这里,平均子组图将提出以下问题:
问题#4:几小时或几天之间是否存在明显差异?
在图 9 中,来自不同周期(1、2、3、4、5)的数据位于同一子组中。当您更改循环时,无需更改子组。因此,可以说,在这些数据的第二次组织中,跨周期差异出现在子组内。这里的组范围图会问以下问题:
问题#5:周期之间的差异是否一致?
在图 9 中,这些不同的腔 (1、2、3、4) 位于不同的子组中。当您更改型腔时,您也更改了子组。因此,可以说,在这些数据的第二次组织中,在子组之间出现了空洞之间的差异。这里的子组平均图还提出了以下问题:
问题#6:空腔之间是否存在明显差异?
米。 9. 将数据组织成子组的第二种方法。
平均值 - 9.54;平均范围为 2.84,导致控制限如图 10 所示。由于 32 个平均值中有 20 个位于控制限之外,因此我们有大量信号需要解释。两天之间有明显的差异,四个腔之间也有明显的差异。此外,从一个周期到另一个周期的变化似乎从子组到子组都是一致的(子组范围的 R 图)。
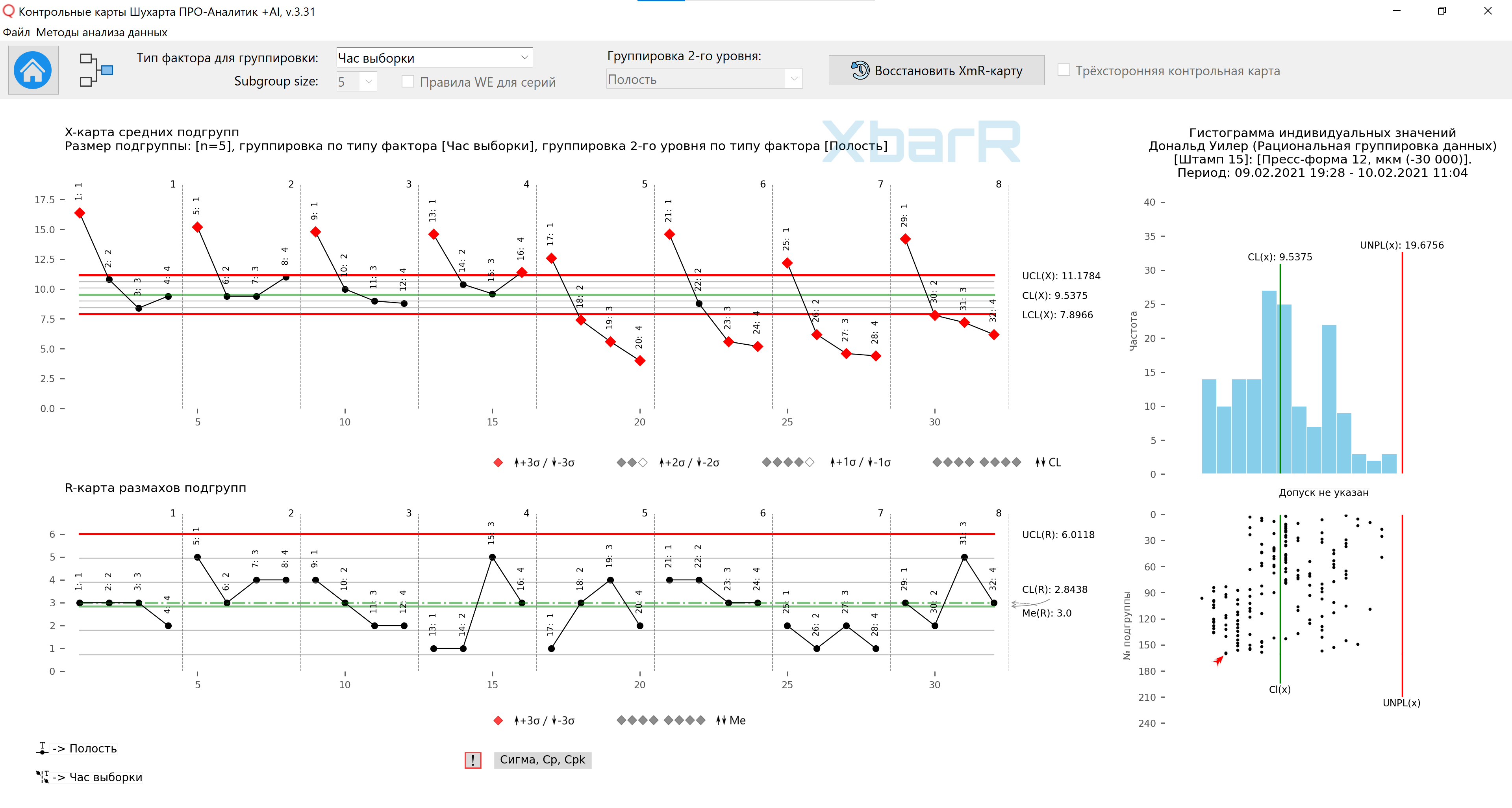
米。 10.第二种组织子组数据方法的子组均值和范围图。用1到8的值划分系列的垂直线是采样的小时数。所有点的签名 - 型腔编号 图纸是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 使用独特的 用于合理数据分组的自动化功能 根据选定的变异来源类型(包含因子的列)和子组的大小构建子组均值和极差的 XbarR 图。
上述两种将数据组织成子组的方法在技术上都是正确的,但在实践中它们并不相同,因为它们没有对数据提出相同的问题。要理解这种差异,请考虑问题#3 和问题#6。
数据的第一次组织产生了问题#3:“空腔之间的差异是否一致?”图 8 中的组范围图对这个问题做出了肯定的回答。腔体之间的差异是恒定的。
第二个组织提出了问题#6,该问题问道:“空腔之间是否存在明显差异?”图 10 中的平均子组图表对这个问题做出了肯定的回答。四个腔之间存在明显差异。型腔 (1) 生产的零件比其他型腔更厚。
除非您了解问题#3 和问题#6 之间的差异,并且了解如何利用这种差异来回答您的问题,否则您将无法理解理性分组。这是一项需要练习和思考的技能。您可以通过回答下一节中的问题进行练习。
将数据组织成子组的第三种方法
Dave 没有使用任何以前的数据组织方式来分组。相反,他在认证测试中使用了将数据组织成子组的方法,如图 11 所示。我们再次使用每行五个值作为大小为五的子组,因此子组与第二个组织中的相同,但现在我们以不同的方式组织它们。我们将为每个腔体提供一个单独的图表,而不是一张包含 32 个子组的图表。
在图 10 中,在固定型腔和循环时,您是否每小时都会更改子组?
那么,在子组内或子组之间可以发现每小时的差异吗?
那么每小时差异将出现在哪里:在极差图上还是在子组平均值图上?
在图 10 中,使用固定的时钟和腔体,当您从一个周期移动到另一个周期时,您是否会更改子组?
那么我们能找到子组内或子组之间周期之间的差异吗?
那么,周期间差异将出现在哪里:在范围图上还是在平均图上?
在图 10 中,使用固定的时钟和周期,当您从一个腔移动到另一个腔时,您是否会更改子组?
那么在哪里可以找到腔体之间的差异呢?
那么腔体之间的差异会出现在哪里呢?
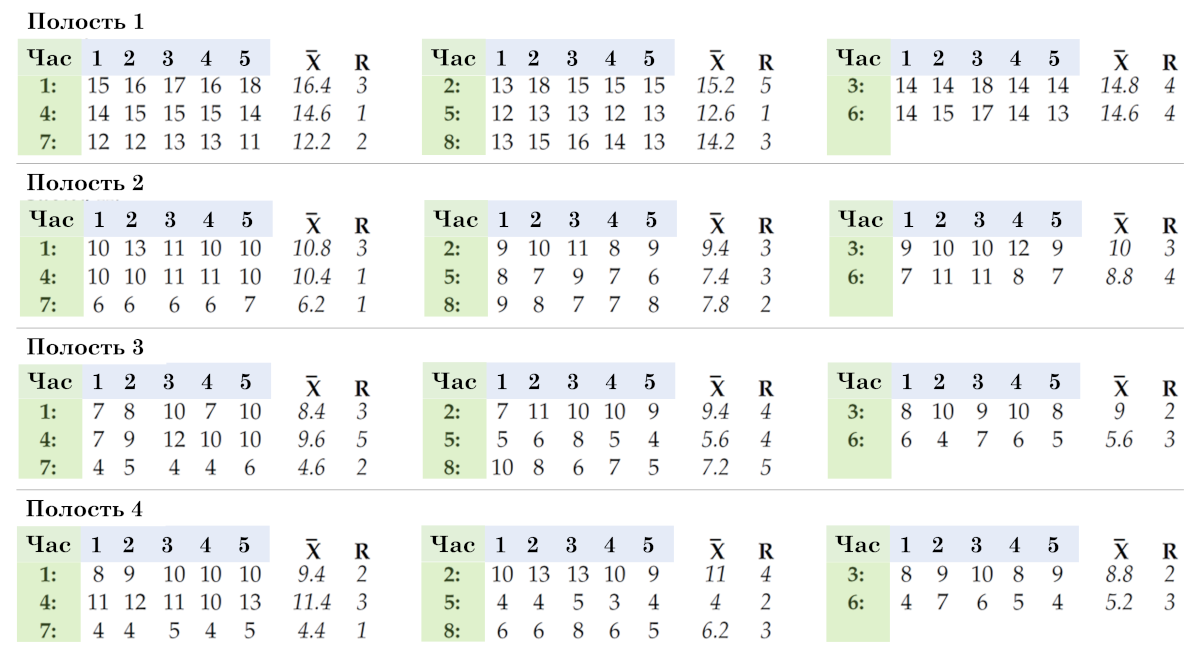
米。 11. 将数据组织成子组的第三种方法。
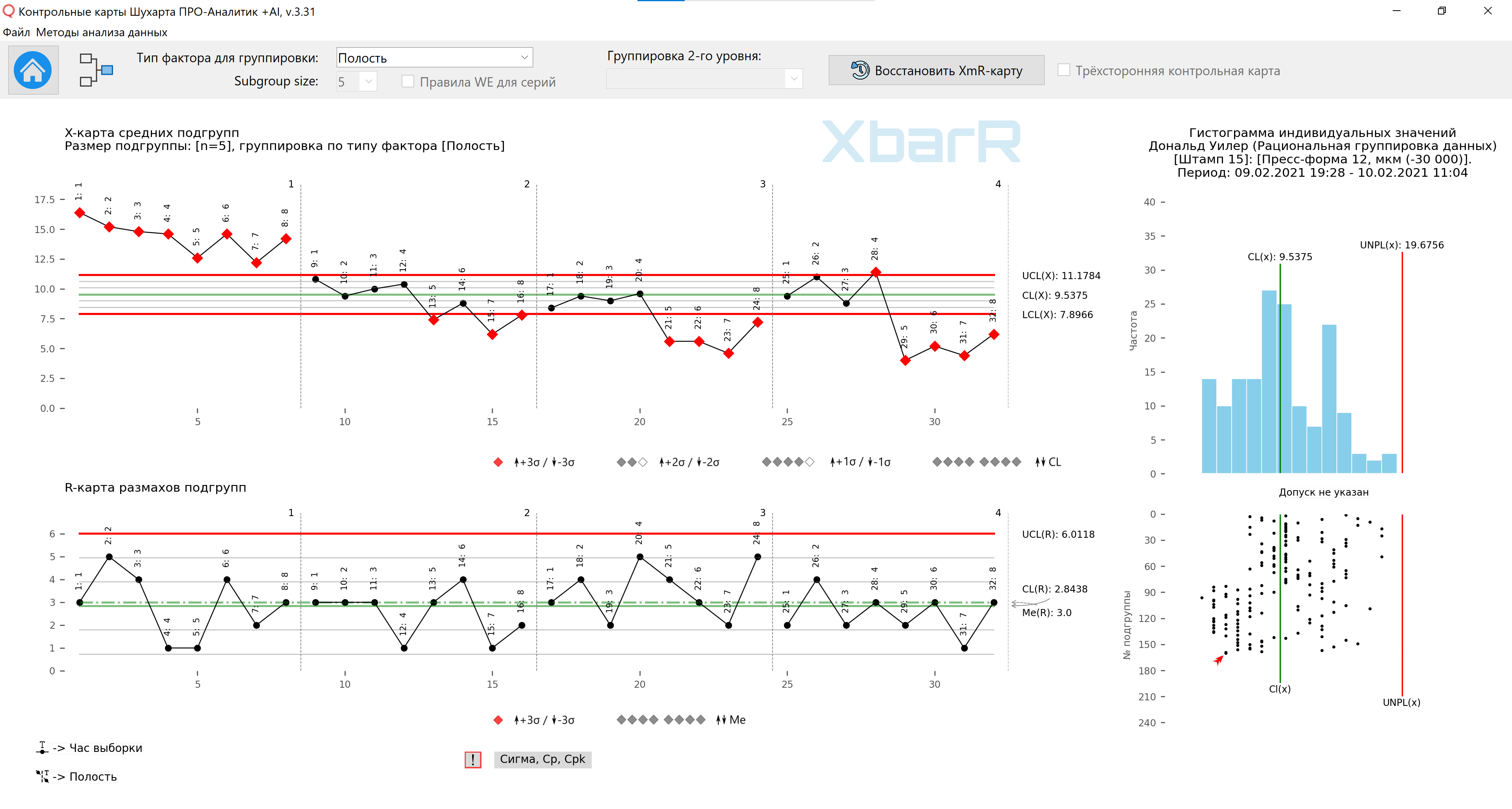
米。 12. 第三种组织子组数据方法的子组平均值和极差图。垂直线划分系列,其值从 1 到 4 - 型腔数量。所有点的签名 - 采样时间。该图纸是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 使用独特的 用于合理数据分组的自动化功能 根据选定的变异来源类型(包含因子的列)和子组的大小构建子组均值和极差的 XbarR 图。
通过在相同的垂直比例上绘制所有四个图表,我们将显示腔体之间的差异。显然,型腔(1)使零件变厚,型腔(2)比型腔(3)和(4)稍厚。根据这些图表,戴夫知道他需要对表格进行调整。由于型腔 (3) 和 (4) 在公差范围内相当居中,因此他要求工具车间将垫片放置在型腔 (1) 和 (2) 后面。
在跨度图中发现了哪些变异来源?手表?周期?蛀牙?
平均图表中的变异来源是什么?手表?周期?蛀牙?
那么上面平均图表上控制限之外的点是什么意思呢?
如果您对前面的问题有疑问,您可能需要再次阅读本文。
您可以继续处理图 12 中的控制图数据,并使用逐次运行控制限制功能,根据可见特征将数据运行划分为各个型腔区域,从而确认模具前后各个流程的运行情况打扫。
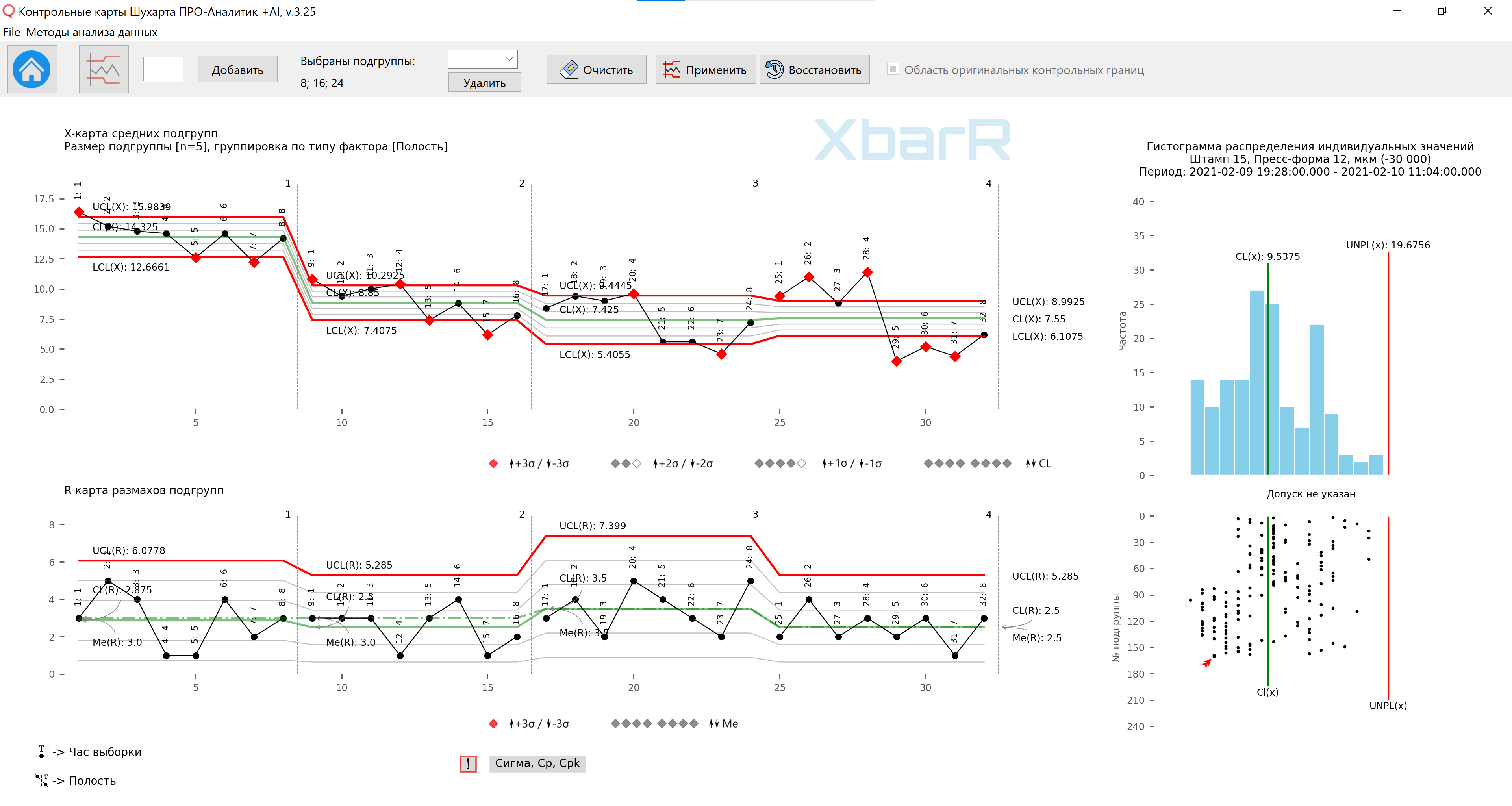
米。 13.第三种组织数据方法的子组均值和范围图,具有各个点系列的控制限。垂直线划分系列,其值从 1 到 4 - 型腔数量。所有点的签名 - 采样时间。该图纸是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 使用独特的 用于合理数据分组的自动化功能 使用以下函数构建按所选变异源类型(含因子的列)和子组大小绘制的均值和子组范围的 XbarR 图表 为各个子组系列构建控制限 。
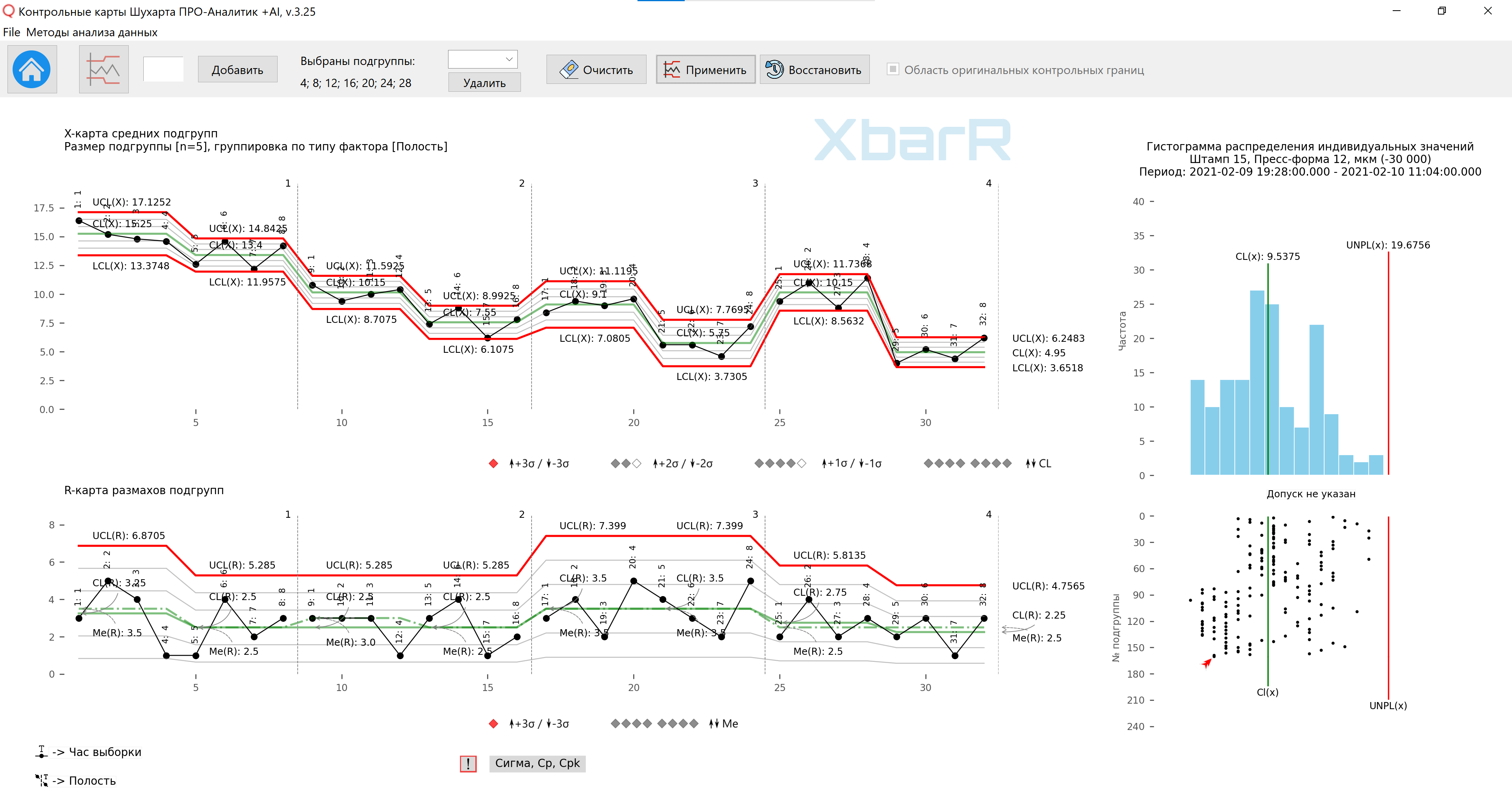
米。 14.第三种组织数据方法的子组均值和范围图,具有各个点系列的控制限。垂直线划分系列,其值从 1 到 4 - 型腔数量。所有点的签名 - 采样时间。该图纸是使用我们开发的 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 使用独特的 用于合理数据分组的自动化功能 使用函数根据选定的变异源类型(包含因子的列)和子组大小构建子组均值和范围的 XbarR 图表 为各个子组系列构建控制限 。
概括。将数据组织成子组
虽然将这些数据组织成子组的所有三种方法在技术上都是正确的,但它们实际上并不等同。不同的组织会提出有关数据的不同问题并对数据做出不同的假设。
图 7 和图 8 中将数据组织成子组的第一种方法测试各个腔的一致性,并寻找时钟和周期之间的差异。
图 9 和图 10 中将数据组织成子组的第二种方法测试运行之间的一致性,并寻找时钟之间和腔之间的差异。为什么这个组织比第一个组织更敏感?
将数据组织成图 11 和图 12 中的子组的第三种方法也测试了周期间的一致性,并寻找小时之间和型腔之间的差异,但通过将型腔放在单独的图表上(图 12),可以更容易地识别该过程中每小时和每天的差异。在组织这些数据的三种方法中,第三种是最好的。
巧妙的数据分组
在子组均值和极差图表中获得问题答案的关键是了解 XbarR 图表的两个部分如何提出不同的问题。您可以通过在子组内放置哪些变异源以及在子组之间放置哪些变异源来控制问题。可能彼此不同的事物应该属于不同的子组。可以相同的事物必须属于同一子组。
例如,当我们将两个测量值放在同一子组中 (n=2) 时,我们得出结论,这两个值是在基本相同的条件下获得的。正是这种判断因素使你的小组变得理性。如果没有这样的判断,你的小组很可能是非理性的。
你永远不应该故意将不同的事物组合在一起。 每个子组在逻辑上必须是同质的。如果你把苹果、橙子和香蕉放在一起,你可能会得到一份不错的水果沙拉,但最终会得到不好的子集。幸运的是,当您系统地将不同的事物分组为子组时,范围图可以提醒您。图 15 显示了图 8 中的范围图。每个子组中都有所有四个空腔。

米。 15. 第一种将数据组织到子组中的方法的子组范围图。
图 15 中突出显示的条带是 1-sigma 条带。我们预计 60% 到 75% 的范围值会落在这个范围内。这里我们得到了 40 个中的 36 个,即 90% 在中心线的 1 西格内。当组跨越中心线时,表示存在分组在一起的不同事物的子组。这种现象的一个常见迹象是在挥杆图中心线的 1 西格玛范围内连续 15 次挥杆。如果发现这种情况,请检查子组内是否可能存在分层。要了解子组内的分层如何影响均值图,请将图 8 中的均值图的控制限(主要是 LCL=4 到 UCL=15)与图 10 中的均值图的控制限(主要是 LCL=8 到 UCL=11)进行比较。
最小化子组内的变异。 背景噪声水平由子组内的变化决定。任何信号都必须在这种噪声背景下寻找。通过最小化子组内的变异,可以最大化过程行为控制图的敏感性。
最大化子组之间差异的机会。 这需要考虑数据流中可能出现哪些类型的潜在信号。如果要比较两个事物,则需要将它们放置在不同的子组中。如果两个事物可能不同,那么它们应该属于不同的子组。
不要将信号隐藏在子组中。 分组仅在子组保持同质的情况下才有效。在许多以参数估计为目标的统计领域,首选大量数据。但这不适用于平均值和极差子组的 XbarR 图。增加子组的大小是打破子组同质性的好方法。由于计算明确假设子组的内部同质性,因此子组的逻辑同质性比子组的大小重要得多。
尊重数据的上下文。 上下文定义了数据的结构,并且是在更改流程时发现变化的具体原因的关键。甚至子组的顺序也很重要。这就是为什么我们通常对图表使用时间顺序。但是,您可以使用其他顺序(如果它们在数据上下文中有意义)。
安全问题
图 8 和 10 中哪个隐含假设不正确?
我们的软件 “Shewhart 控制图 PRO-Analyst +AI(适用于 Windows、Mac、Linux)” 已包含准备好的 Excel 文件,其中包含本文的数据。